人工智能公共數據 你所知道與未知的全景解讀

人工智能(AI)作為當今科技領域的核心驅動力,其發展離不開海量數據的支持。公共數據作為其中的重要組成部分,不僅是技術進步的基石,也深刻影響著社會生活的各個方面。本文將系統梳理人工智能公共數據的已知與未知,揭示其多維度的價值與挑戰。
一、已知領域:公共數據如何賦能人工智能
- 定義與類型:人工智能公共數據通常指由政府、科研機構、非營利組織等公開提供的、可被廣泛訪問和使用的數據集。常見類型包括:
- 政府開放數據:如人口統計、交通流量、環境監測數據。
- 科研數據集:如圖像識別領域的ImageNet、自然語言處理的Wikipedia語料庫。
- 公共領域數據:如歷史檔案、文化遺產數字化資源。
- 核心價值體現:
- 訓練與優化模型:高質量公共數據集(如COCO、MNIST)是機器學習模型訓練的基礎,推動計算機視覺、語音識別等技術的發展。
- 促進科研協作:公開數據降低研究門檻,加速學術進展與跨領域合作。
- 驅動社會創新:例如,城市交通數據助力智慧交通系統開發,氣象數據支持氣候預測與災害預警。
- 典型應用場景:
- 醫療健康:公共醫療數據用于疾病預測模型與藥物研發。
- 城市治理:整合公共數據優化資源配置,提升公共服務效率。
- 教育科研:開放學術數據推動知識共享與教育公平。
二、未知領域:公共數據的潛在挑戰與前沿探索
- 數據質量與偏見問題:
- 未知偏見:數據集中可能隱含的文化、性別或地域偏見,導致AI模型產生歧視性輸出(如招聘算法中的性別偏向)。
- 質量參差:數據標注錯誤、覆蓋不全等問題影響模型可靠性,且難以全面檢測。
- 隱私與安全邊界:
- 匿名化失效風險:即使脫敏的公共數據,通過跨庫關聯仍可能重新識別個人身份。
- 惡意利用可能:公開數據可能被用于訓練深度偽造、自動化攻擊等有害AI應用。
- 治理與倫理困境:
- 權屬與授權模糊:數據來源的合規性、原創者權益保護缺乏全球統一標準。
- 生態失衡:數據資源集中于少數機構或國家,可能加劇技術壟斷與數字鴻溝。
- 前沿趨勢與未知可能性:
- 合成數據興起:為保護隱私,使用AI生成的仿真數據替代真實數據成為新方向,但其真實性和有效性仍需驗證。
- 聯邦學習突破:在數據不出本地的前提下進行聯合建模,試圖平衡數據利用與隱私保護,但技術成熟度與效率仍是未知數。
- 量子計算影響:未來量子計算可能徹底改變數據加密與處理范式,為公共數據應用帶來顛覆性變革。
三、未來展望:構建可信賴的公共數據生態
- 完善數據治理框架:建立跨領域的數據質量標準、倫理審查機制與國際協作協議。
- 技術創新與法規并行:發展隱私增強技術(如差分隱私),同步推進數據安全立法。
- 推動普惠包容:鼓勵多元主體參與數據共建,避免邊緣群體在AI時代被進一步忽視。
人工智能公共數據既是機遇的源泉,也是挑戰的試金石。只有通過科學管理、技術創新與全球協作,才能充分釋放其潛力,引導人工智能向以人為本、可持續的方向發展。未知領域的存在并非障礙,而是驅動我們持續探索、完善規則的動力——這或許正是AI時代最值得期待的部分。
最新產品
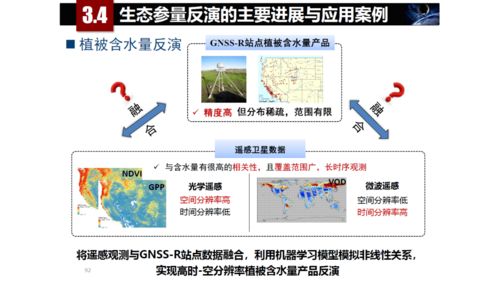
院士觀點丨李德仁 物聯網、大數據與人工智能驅動下的定量遙感及人工智能公共數據發展
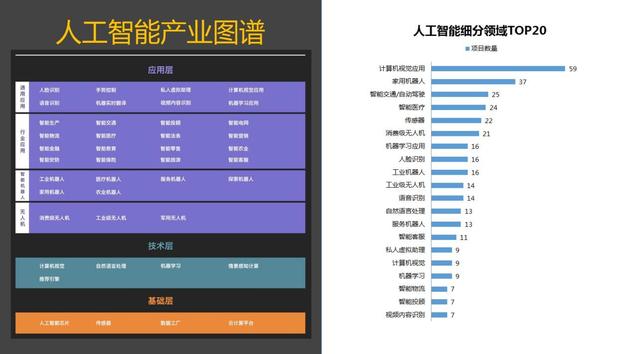
人工智能產業圖譜揭示未來 在AI+時代,公共數據如何開啟新機遇?
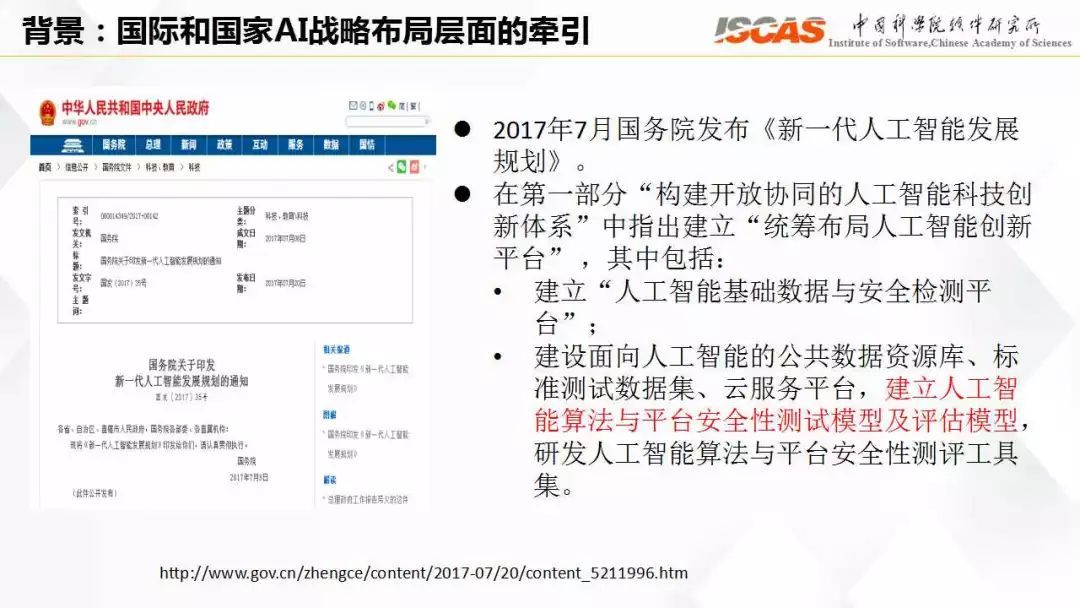
中國首個人工智能深度學習算法標準與公共數據 內涵、意義與未來展望
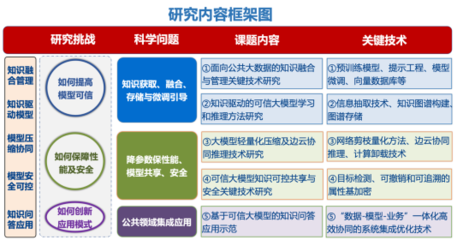
人工智能新里程 貴州大學領銜重大專項,可信大模型關鍵技術研究獲突破
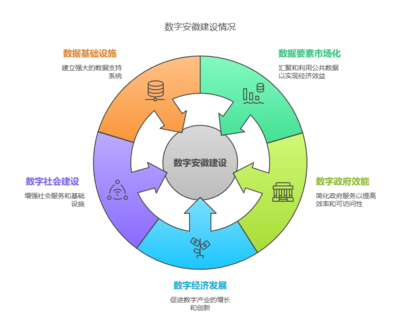
數字安徽建設邁入快車道 公共數據超3400億條,為人工智能發展注入強勁動能

索尼啟動人工智能產品全面倫理審查,聚焦公共數據安全與責任

青島知識產權數字經濟產業峰會暨2020年知識產權宣傳周活動在青島西海岸新區舉行

智能汽車時代 數據與算法雙輪驅動,公共數據開啟軟件價值新篇章
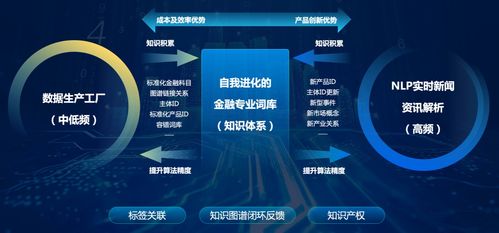
數庫科技邀您共聚2021世界人工智能大會,探索人工智能公共數據的未來

數據中心引入人工智能 是超前布局還是為時過早?